
Is AI truly intelligent?
It's time for a modern version of the Turing Test

Anyone who has heard me talk or read my newsletter knows I am a strong proponent of AI. I believe it has forever changed the landscape, across numerous fields and occupations. However, is AI truly “intelligent”? That is a difficult question to answer, in large part because there is no single definition of intelligence.
We will provide our own definition of intelligence in a moment, but first, let’s consider how we could make such an assessment. The basic options are:
Look at the internals of the mechanisms and derive a formal proof showing that an AI exhibits intelligence
Collect observations and determine with some degree of confidence whether the AI exhibits intelligence
For those of you in the domain of mathematics, there exists a class of problems that fall within the first category. Math is about the only thing you can actually prove. It is difficult to know almost anything else with 100% certainty. I could prompt an AI 100 times in a row and each response could be intelligent. However, I can’t prove that the 101st prompt won’t yield an unintelligent response? It is easy to prove a negative, as I only need to find one case that does not conform. You can then posit that even intelligent people have a bad day, so we could decide on a threshold of “correct” answers. However, what would that threshold be in order for an entity to be considered intelligent?
Even in the world of software engineering itself, very few programs can be proven accurate. For those that have formal proofs, the proof is usually an order of magnitude longer than the code itself. Once a program reaches even a small number of control bits or parameters, there exists an exponentially large set of possible test cases. Consider that a piece of software with only 20 independent states already has over half a million possible permutations. It is not feasible to write that many test cases, although with AI, that may change.
Nonetheless, engineers and testers create test plans that cover as much of the functionality as they can. The results of this testing lead to a decision about whether the software “works” and is ready to be deployed into production. The internals of software implementations, including AI systems such as Large Language Models (LLMs), help augment our understanding of what we observe, but they aren’t enough to prove accuracy.
This software testing process mirrors the second approach we outlined, observation, which also forms the basis of science. Scientists make a hypothesis and design an experiment to validate it. The experiment needs to be measurable and repeatable. Scientists collect the data and determine their confidence level in the hypothesis.
Beyond the Turing Test
For decades in Computer Science, the baseline experiment used in AI was the Turing Test. Also known as the Imitation Game, this tested whether participants could discern which of two chat conversations was with a computer rather than a human.
A recent study found that ChatGPT 4 passed the test in 49.7% of games. Anyone who has used an AI chatbot knows they write like humans do. They were trained on vast amounts of human-written text. Now, continuing the tradition of moving the AI goalposts, the Turing Test is no longer a great assessment of actual intelligence. It heavily relies on linguistic style and social cues. For example, the AI might find it beneficial to periodically include a typo in a response to appear more human. Understanding emotions and exhibiting imperfections come into play. While these things are important for human interaction, they don’t fit neatly into our search for intelligence.
IQ as a standard measure of intelligence
Any single test is sure to attract criticism due to the complexity of human intelligence. The Intelligence Quotient, or IQ test, is no exception. Yet, despite its various criticisms, it remains the most widely accepted benchmark of cognitive capabilities. It is designed to assess logical reasoning skills, problem-solving, and verbal comprehension. The IQ numerical score represents an individual's intelligence relative to the general population. The test is calibrated so that the average score is 100, adjusted for a person’s age.
Another study administered only the text-based questions from a self-scoring IQ test to a number of LLMs. They did remarkably well, with ChatGPT 4 scoring a 121, putting it in the 92nd percentile and garnering a Stanford-Binet categorization of “Superior.” That doesn’t qualify it for Mensa, so apparently it still has some work to do.
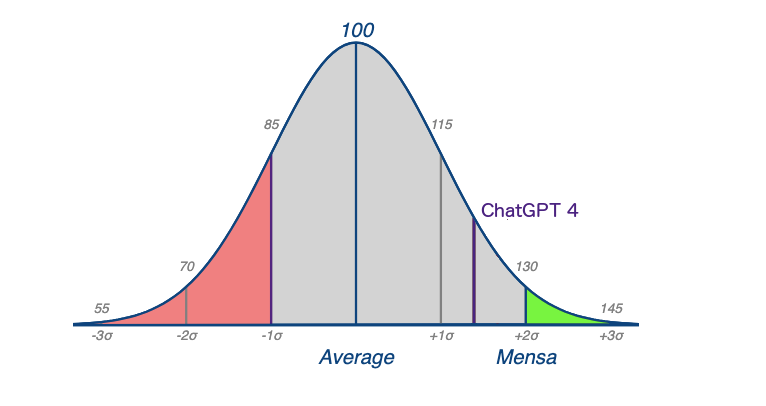
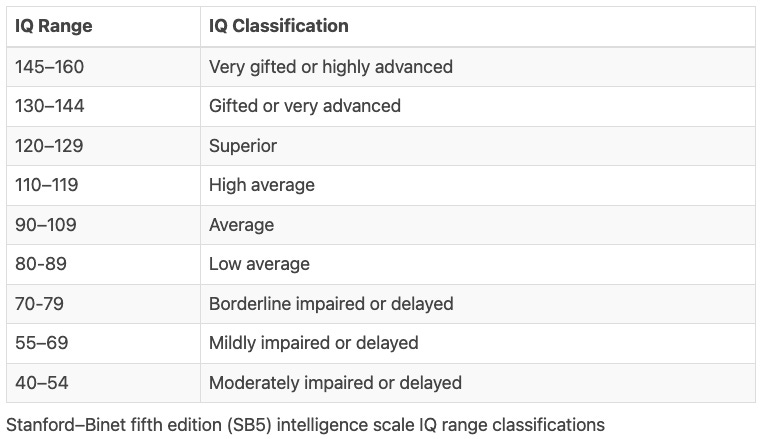
For reference, the following table shows the range of Stanford-Binet classifications. Both tail ends of the IQ score distribution have fine-grained categories. It is widely theorized by scientists that Einstein had an IQ score of around 160, although there is no documented evidence he ever took a standardized test.
Unfortunately, there were two major flaws with the AI IQ experiment discussed above.
Only the verbal portion of the IQ test was given. Current AI models are capable of reasoning over images, so the entire IQ test should be used to get a more accurate assessment.
The self-scoring IQ test is published in materials potentially available to AI models. Thus, these exact questions could have been part of its training set. The LLM may not truly know the answer, it’s possible that it just “remembered” the answer.
Both of these flaws are incredibly important. The only part of the IQ test that was used was the part that AI is really good at. Consider that an LLM is trained on language or written text. Thus, it isn’t much of a stretch to posit that it will perform better on the verbal portion of the test than on spatial or numerical topics.
The second flaw is more subtle. It makes getting a definitive measurement of intelligence quite challenging. In general, official tests of any type are usually proctored and test questions are safely guarded to avoid this type of “cheating”.
The challenge for researchers then becomes you need to either get access to these safely guarded test questions, or you need to make up your own. However, if you construct new questions, they won’t be calibrated. An IQ score is based on an average of how a sample population performs on the test, so you would then need to spend significant time and money to baseline the new test questions.
If we had the time and resources, we could overcome these hurdles. However, I would argue this is not the right AI assessment mechanism. The IQ test attempts to measure intelligence in a contrived fashion. If we look at the world, what do truly intelligent people do? They don’t just learn new things or take tests. They create new knowledge!
Levels of intelligence
Now, we finally get to our own working definition. Intelligence is not just one thing, as evidenced by the fact that most tests encompass several areas including verbal, numeric, and spatial. Intelligence is comprised of a set of capabilities that we commonly lump together under one umbrella definition.
We will build a systematic definition, starting with what I’ll call a primitive. The relevant dictionary definition of a primitive is an entity with “the character of an early stage in the evolutionary or historical development of something.” A primitive is fairly general. It can be a piece of knowledge, a process, or a skill of value.
When we are young, we begin to learn primitives such as:
Letters of the alphabet and sounds
Numbers and counting
As we age, we go on to learn additional primitives based on the foundational ones mentioned above. This includes:
Forming words by combining letters
Creating simple sentences from those words
Mathematical operations on numbers such as addition and subtraction
We continue to add primitives until we build up higher-level skills, such as writing an essay or finding a mathematical proof for a problem. It turns out that everything is relative. Even writing a paper can be considered a primitive when the end goal is to convince your boss of a strategy you came up with. You might write a 6-pager describing the business case and then follow up with a presentation. Writing the paper, while valuable and intelligent, was only a stepping stone to the end goal or accomplishment.
Science works this way in that various theories are established through experiments, and then those findings are used to discover other things in other studies. Computers work the same way. At the most basic level, a computer is made up of gates that represent only a one or a zero. From there, computers use primitives that define how a set of bits together forms a byte, and different byte values can represent a letter, a number, or some other symbol. Additionally, we can define primitives that operate on this data, such as performing multiplication or division. Eventually, we add enough primitives that we can build an astronomically complex piece of software such as an AI system.
We can use the term knowledge in place of primitive in order to be more accessible to a general audience. Given these foundational definitions, we can define intelligence as a spectrum.

The levels of intelligence are:
Acquire knowledge (or “primitives”): Intelligent students are able to learn. We have already seen that almost all knowledge is based on other existing knowledge. You need to understand the primitives before you can move forward.
Apply that knowledge: For example, once I know how to add numbers, I can apply that concept to tasks such as managing inventory or balancing a checkbook.
Create new knowledge: Researchers and innovators don’t just apply existing knowledge, they create new knowledge. They come up with new ideas and discover new truths about the world. They do this through experimenting and combining existing primitives in unique ways.
Today’s AI systems operate at the level of practitioner in numerous fields, the middle layer of intelligence in our scheme. Let’s examine how AI relates to each level of intelligence.
It is clear that AI can acquire knowledge. In the early days of AI, knowlwedge was encoded explicitly. Rules-based systems used clauses within a propositional logic model. Programs like Deep Blue were code with logic very specific to the game of chess, including libraries of opening moves and end game scenarios.
More recently, machine learning approaches allowed the systems to create their own representations using complex mathematical model to encode knowledge. Users of AI chatbots can easily observe that they know many things. Because large language models have been trained on such an expansive amount of written text, they have a knowledge base more vast than almost any other software.
Today’s AI system are practitioners in that they can apply knowledge they have learned. This is generally called inference. If you asked, "How long would it take to drive from New York City to Los Angeles?", the LLM likely has not already stored the exact travel time. However, it knows the approximate distance between the two cities is around 2,800 miles, and it has knowledge of typical highway driving speeds. From this, it can infer an estimate that the driving time would be around 40-45 hours of continuous driving.
LLMs can make straightforward factual lookups and combine multiple data points learned from its training to produce inferred responses. It can do this even for questions it wasn't explicitly trained on. The complexity of inferences depends on the model's general knowledge and reasoning capabilities. There are some domains where AI excels at this today. Coding, or writing software, is a use case tailor made for AI systems. It can recognize patterns in the input prompt, apply that to stored patterns it has learned, and generate code based on other learned patterns that apply to the problem domain. In verbal or written domains, AI excels. In other domains such as mathematical proofs and reasoning, there is still much progress to be made.
This is where we reach the outer limits of today’s AI systems. A human researcher, scientist, or inventor is able to go beyond inference to our final level of intelligence, knowledge creation. They can discover and create new knowledge using existing primitives. Consider the early days of mathematics where people looked at the existing primitives of numbers and addition, and they discovered the commutative property of addition. This property states that the order of numbers in addition does not change the sum. For example, 2 + 5 = 7 and 5 + 2 = 7. This example seems obvious, but as the field of mathematics was beginning, these primitives were not yet known or documented.
A modern version of the Turing Test
Once an AI system reaches the level of Researcher and is able to discover or create new knowledge, it will be seen as truly intelligent. This requires the ability to go beyond inference from learned information in its training data set. It requires the creation of new knowledge based on existing (learned) primitives. Alternatively, if it can accurately predict future events with a high degree of accuracy, it can also be considered intelligent.
In summary, it needs to exhibit intelligence by generating knowledge not currently available. A formal definition of the Researcher (Turing) Test is as follows.
A software system is considered intelligent if it can do one of the following given a knowledge set acquired through training { k1, k2, … kn }:
The system can accurately generate a novel knowledge primitive kn+1 that was not generally available either in its training set or to researchers in the field.
Given that the knowledge training set was acquired prior to time t, the system can accurately predict events { p1, p2, … pm } at time(s) greater than t+1. Each prediction can be accompanied by a confidence level (percentage), and the system is evaluated based on its calibration over the set of predictions (for example, if the average of the prediction confidence levels is 85%, then the system should be correct in at least 85% of its predictions).
Today’s AI models admittedly cannot do this. Both Claude and ChatGPT say so.

Unlike the Turing Test, the Research Test cannot be verified in a matter of minutes. It could take days, weeks, or even months to verify whether a system passes this test. This is due to the time required to verify the new findings (as is the case with any new published research paper), or for the calendar time to elapse such that observers can determine whether the predictions occurred as stated.
It is not unreasonable to posit that it takes time to ascertain intelligence. If you sit down with a person for an hour, can you truly determine if they are intelligent or not? During interviews, some candidates are polished and well-prepared, but end up being poor performers once they enter the workplace. It can be difficult to assess capabilities in such a short amount of time.
In our next issue, we will look at whether AI will reach this milestone and become truly intelligent.